人工智慧與數位人文 - 中國歷代人物傳記資料庫同仁(2024-2025)第一場報告
中國歷代人物傳記資料庫(CBDB)專案同仁於2025年5月15日至16日在波士頓劍橋發表了他們的研究成果。
5月15日的發表會在CGIS Knafel大樓K354舉行。當天共分為兩個場次。第一場的主題是社會網絡分析(SNA),本場次的發表內容包括:
書寫如何建構佛教歷史記憶:以唐代僧人數據爲中心的反思 投影片下載
熊钿(中國歷代人物傳記資料庫訪問學者,來自河南大學)
本次彙報以唐代僧人群體爲切入點,通過對2800餘條數據的梳理,分析佛教史書寫中存在的類型選擇、性別排除與敘事結構變遷。以馬祖道一及“洪州宗”爲例,探討禪宗如何通過“祖師譜系”式的單一線性敘事,取代早期“十科分類”的多元結構,從而確立起宗派話語地位的。

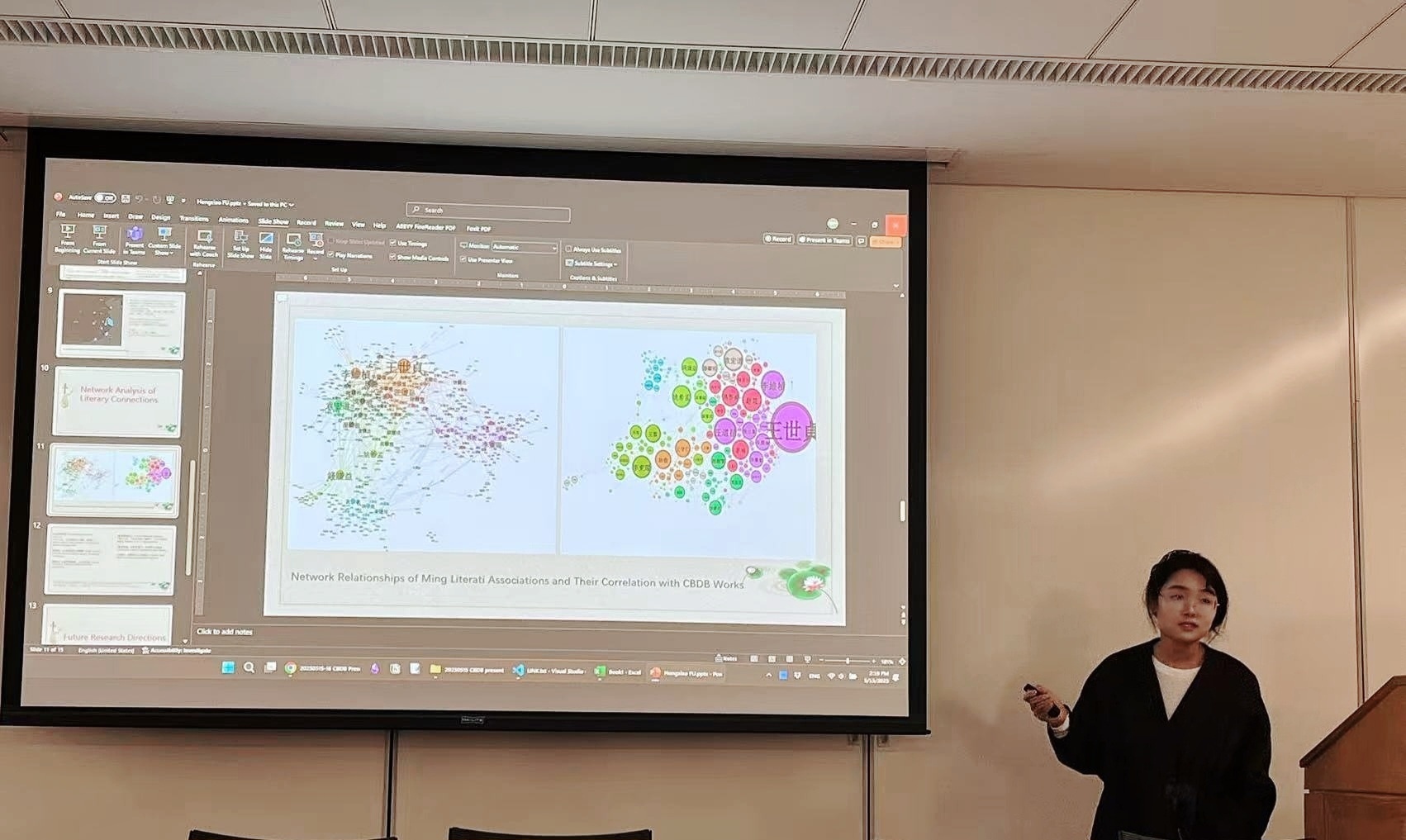
明代結社文人地理分佈與構成研究 投影片下載
伏虹晓(中國歷代人物傳記資料庫訪問學者,來自浙江大學)
本研究首次採用大語言模型(LLM)進行數據提取,實踐表明該方法兼具準確性與高效性,不僅大幅提升了結構化數據的處理效率,還爲CBDB拓展了新的數據來源渠道。
明代文人結社規模堪稱歷代之最。本研究選取其中與CBDB匹配的一千餘位人物作爲樣本,通過分析其地理分佈特徵及在社中佔比,深入探討文人結社與鄉黨關係之間的內在關聯;同時考察結社時間分佈與朝代更迭的潛在聯繫。基於社會網絡關係圖譜,本研究進一步揭示了明代文學人物的結社偏好,由此窺見明人如何通過結社構建“文權”與“政權”。
第二場的主題是「書信」:
階層·地方·文本:明代實物書信中的關係網絡 投影片下載
韩明亮(中國歷代人物傳記資料庫訪問學者,來自浙江大學)
大批量的明代實物書信是理解文本與世界關係的重要窗口。可視化工具讓書信分析得以從整體上展開比較考察,由此看到明代實物書信在文化與文獻層面的獨特景觀。明代實物書信中一個突出的角色是以方用彬爲收信人的800餘通書信,這批書信寫信人的空間分佈與寫信數量構成的頻次比較,系統展現了晚明徽州商人在精英社會中的活躍程度,並藉助這一社會切片理解不同階層之間密切互動的晚明景觀。在這一批獨特的文獻之外,蘇州群體內部的書信集群呈現出均勻且密切的分佈特徵。蘇州內部圈層化的多元溝通網絡有三方面的社會動力:家族、師徒和文化活動。以上兩大文獻集群構成對中晚明理解的兩大歷史切片。掌控數以千計實物文獻重塑理解歷史新視角,在生髮快感的同時,也帶給我們一種歷史的文獻迷思。我們藉助實物書信生產與收藏的歷史語境、辨僞、文物流轉與檔案管理等多重文獻脈絡梳理,嘗試揭示這種歷史切片被選擇的必然。

明代核心人物群:“名公”群體通信與時空分析
陈泓安(中國歷代人物傳記資料庫訪問學者,來自浙江大學)
本次彙報以《國朝名公翰藻》書信總集(明萬曆十五年刻本)爲基礎,選取截至萬曆十五年的明代文學、文化、思想界核心人物——“名公”群體作爲研究核心,通過整理其書信往來中的書信作者與收信人信息,構建出一幅初步的明代名公社會關係網絡與地理分佈圖譜。在尚未完成全部收信人身份識別的基礎上,本研究聚焦於名公彼此之間的通信,分析其在時空維度上的聯繫與演化特徵,揭示其背後的歷史與社會背景,作爲後續深入研究的基礎。此外,本次還將展示LLM在收信人身份識別方面的輔助作用。

如何脫穎而出:明代藝術家的交往圖譜
庄宇宁(中國歷代人物傳記資料庫訪問學者,來自東南大學)
本研究以《中國美術家大辭典》爲數據基礎,構建了一套處理現代出版物中複雜版式內容的標準化流程,並結合“明代書信計劃”中的通信數據,提取具備書信記錄的藝術家群體,探討藝術家如何通過交往建構聲望與文化地位。研究發現,社交網絡中的核心人物多爲政治家或文人,而非典型的藝術創作者,且藝術家的地理分佈與明代進士高度重合。這一結果引發了對《中國美術家大辭典》在界定“藝術家”身份時標準是否過於寬泛的反思。爲進一步探討藝術家在交往互動中如何確立其審美權威,本文以文徵明爲個案,結合《甫田集》、《雅債》、CBDB等多源數據重構其社會關係網絡與交往形式。儘管不同數據源所生成的網絡圖在結構上存在顯著差異,但它們從不同角度拓展了對藝術家群體的觀察和思考。

5月16日的發表會在CGIS S050舉行。當天同樣分為兩個場次。第一場的主題是:沒有專業領域知識的技術學者如何為人文研究專案做出貢獻:
複雜親屬關係網絡可視化
Luo, Queenie(中國歷代人物傳記資料庫研究助理,哈佛大學東亞系博士生)
本次報告將介紹一款專爲中國歷代人物傳記資料數據庫(CBDB)設計的新型親屬關係網絡可視化工具。CBDB 包含數百萬條人物傳記記錄,其中包括諸如父子關係及擴展家族聯繫等詳細的親屬關係數據。儘管該數據庫的數據極爲豐富,目前卻缺乏能夠有效體現其複雜歷史親屬結構的可視化工具。現有的家譜可視化方案往往過於簡化,難以展現 CBDB 中多代、多向的親屬關係。本工具通過構建一個可擴展、聚焦於家譜學的可視化框架,克服了上述侷限,顯著提升了 CBDB 親屬數據的可達性與可讀性。報告將展示該工具的具體使用方法,並徵求公衆意見,以進一步完善與擴展該平臺的功能。
基於大語言模型的明代人物消歧模型構建研究
刘贞伶(中國歷代人物傳記資料庫訪問學者,來自北京大學)
本研究聚焦於歷史人物記錄中的姓名消歧問題,旨在構建一個基於人物消歧的判別模型,以識別這對同名者是否爲同一人物。以《明代職官年表》爲數據基礎,每條人物記錄以結構化格式呈現。以維基百科作爲人物消歧的參考,並藉助大語言模型將人物記錄與維基百科內容進行語義匹配。在此框架下,研究構建成對樣本集,結合文本相似度、任職時間差異、官職層級等多維特徵,訓練二分類模型以輸出相似度得分。所構建模型支持對能鑲嵌進此空間的同名人物進行消歧判斷。
《四庫全書》數據挖掘中得出的發現 投影片下載
郑钰骐(中國歷代人物傳記資料庫研究助理,哈佛大學本科生)
本次彙報將介紹我學習數據挖掘的三個階段。我首先復現了已處理的蘇州數據。這一過程幫助我覈對了第一批四庫全書的內容,並將類似的分類方法應用於第二批內容。我將討論在處理過程中遇到的挑戰,例如縮進、格式和顏色上的差異,以及我們如何根據每批數據的特點制定個性化的解決方案。爲提升內容導向型標註的準確性,我引入了“標題”和“副標題”等新標籤。彙報還將評估在追求標註精度與代碼複用性之間所需的平衡,重點分析在第二批數據中按樣式排序的侷限性。最後,我將比較 docx 和 pypandoc 等工具包各自的優劣,並分享一些可能對未來項目有參考價值的模式識別技巧。

第二場的主題是地理信息系統(GIS):
大語言模型時代的中國古代戲曲作家數據挖掘與研究 投影片下載
陈红艳(中國歷代人物傳記資料庫訪問學者,來自湖北大學)
本次彙報聚焦元、明、清三代中國古代戲曲作家的數據挖掘與分析,探索在大語言模型(LLMs)快速發展背景下,數字技術如何助力戲曲作家群體研究。通過地理可視化與統計分析,系統揭示戲曲作家籍貫分佈的空間格局及其歷史演變特徵,剖析其與區域社會文化結構的互動關係。在整體分析的基礎上,本報告以江南地區爲個案,深入探討其成爲戲曲創作中心的時空路徑與機制。
歷代中國翻譯家數據挖掘與研究
胡伊伊(中國歷代人物傳記資料庫訪問學者,來自復旦大學)
本研究以中國歷代翻譯家爲研究對象,立足於數字人文的跨學科視角,綜合運用數據挖掘、地理信息系統(GIS)與可視化技術,系統分析不同時期翻譯家的數量分佈、空間格局及其歷史演變特徵。研究首先構建包含生卒年、籍貫、譯作等多維度要素的翻譯家數據集,基於歷代統計數據考察翻譯家在地域上的集聚與遷移趨勢,揭示政治、文化、宗教、制度等多重因素對翻譯活動空間分佈的影響。在總體分析的基礎上,研究進一步聚焦唐、遼、宋、西夏、元、明、清等具有代表性的歷史階段,選取上述階段典型翻譯家群體並開展個案研究,探索在特定歷史語境下翻譯活動的制度安排、跨文化互動路徑與知識傳播機制。通過宏觀趨勢與微觀實例的結合,旨在爲中國翻譯史的時空結構研究提供新的數字證據與解釋框架。
誰推動了改革——試論晚清地方大幕的成員結構及地域分佈 投影片下載
闫力元(中國歷代人物傳記資料庫訪問學者,來自復旦大學)
我的報告聚焦晚清改革的核心問題:“誰在推動改革?”。我的研究將以曾國藩、張之洞、李鴻章三位重臣的幕府爲中心,運用群體傳記學和數據可視化方法,系統考察幕僚的籍貫地域、社會階層、及其參與的幕府活動(如軍事、政事,特別是洋務)。通過量化分析與思想史解讀相結合,期望能更清晰地描繪出晚清改革力量的構成、地域分佈特徵及其背後的思想動因,爲理解晚清變革提供一個基於數據的新視角。在本次報告中,除了基本的數據介紹,我會先回顧學界在晚清幕府、改革動力及參與主體等方面的研究成果,明確本研究的切入點,並介紹目前這一研究的進展。

中國歷代人物傳記資料庫(CBDB)專案主任包弼德教授;Digital China Initiative(DCI) 專案執行主任鄧國亮博士;CBDB 專案經理李倚天;以及各位發表人皆為此次豐富且深入的討論做出了貢獻。

CBDB助理專案經理潘小莹;哈佛藝術與人文研究運算(Harvard Arts & Humanities Research Computing)部門的資深軟體工程師 Kevin Lin; 東亞語言與文明系訪問學者林文州;哈佛大學訪問學者楊玉娟;以及CBDB數據科學貢獻者 Cheng, Chao 亦參加會議。CBDB資深專案經理王宏甦主持了所有發表會議程。